Friday, June 8, 2012
Lecture 21: Statistical Machine Translation (2/2) (8/6/12)
IBM models for word alignment. Many-to-one and many-to-many alignments. IBM model 1 and the HMM alignment model.
Training the alignment models: the Expectation Maximization (EM) algorithm.
Symmetrizing alignments for phrase-based MT: symmetrizing by
intersection; the growing heuristic. Calculating the phrase translation
table. Decoding: stack decoding. Evaluation of MT systems. BLEU.
Log-linear models for MT.

Lecture 20: Statistical Machine Translation (1/2) (5/6/12)
Introduction to Machine Translation. Rule-based vs. Statistical MT. Statistical MT: the noisy channel model. The language model and the translation model. The phrase-based translation model. Learning a model of training. Phrase-translation tables. Parallel corpora. Extracting phrases from word alignments. Word alignments.


Friday, June 1, 2012
Lecture 19: computational discourse (prof. Bonnie Webber)
Discourse structures and language technologies: computational discourse. What is discourse? Discourse and sentence sequences. Discourse and language features. Discourse structures. Current computational discourse modelling. Topic structure and segmentation. Functional structure and segmentation. Examples. (Lexicalized) Coherence relations. Other lexicalizations of discourse relations. No discourse relations. Discourse-enhanced Statistical Machine Translation.

Thursday, May 31, 2012
Seminar by Prof. Mark Steedman: The Statistical Problem of Language Acquisition (31/05/12)
Title: The Statistical Problem of Language Acquisition
Speaker: Mark Steedman (Informatics, University of Edinburgh)
When: Thursday 15.45
Where: Aula Seminari, Via Salaria, 113 (third floor)
Abstract:
The talk reports recent work with Tom Kwiatkowski, Sharon Goldwater,
and Luke Zettlemoyer on semantic parser induction by machine from a
number of corpora pairing sentences with logical forms, including
GeoQuery, ATIS, and a corpus consisting of real child-directed utterance from
the CHILDES corpus.
The problem of semantic parser induction and child language acquisition
are both similar to the problem of inducing a grammar and a
parsing model from a treebank such as the Penn treebank, except that
the trees are unordered logical forms, in which the preterminals
are not aligned with words in the target language, and there may be
noise and spurious distracting logical forms supported by the context
but irrelevant to the utterance.
The talk shows that this class of problem can be solved if the child
or machine initially parses with the entire space of possibilities
that universal grammar allows under the assumptions of the Combinatory
Categorial theory of grammar (CCG), and learns a statistical
parsing model for that space using EM-related methods such
as Variational Bayes learning.
This can be done without all-or-none "parameter-setting" or attendant
"triggers", and without invoking any "subset principle" of the kind
proposed in linguistic theory, provided the system is presented with a
representative sample of reasonably short string-meaning pairs from
the target language.
Bio: Mark Steedman is Professor of Cognitive Science in the School of
Informatics at the University of Edinburgh, to which he moved in 1998
from the University of Pennsylvania, where he taught as
Professor in the Department of Computer and Information Science. He
is a Fellow of the British Academy, the Royal Society of Edinburgh,
the American Association for Artificial Intelligence, and the European
Academy.
His research covers a range of problems in computational linguistics,
artificial intelligence, computer science, and cognitive science,
including syntax and semantics of natural language, and parsing and
comprehension of natural language discourse by humans and by machine
using Combinatory Categorial Grammar (CCG). Much of his current NLP
research concerns wide-coverage parsing for robust semantic
interpretation and natural language inference, and the problem of
inducing such grammars from data and grounded meaning representations,
including those arising in robotics domains. Some of his research
concerns the analysis of music using robust NLP methods.

Speaker: Mark Steedman (Informatics, University of Edinburgh)
When: Thursday 15.45
Where: Aula Seminari, Via Salaria, 113 (third floor)
Abstract:
The talk reports recent work with Tom Kwiatkowski, Sharon Goldwater,
and Luke Zettlemoyer on semantic parser induction by machine from a
number of corpora pairing sentences with logical forms, including
GeoQuery, ATIS, and a corpus consisting of real child-directed utterance from
the CHILDES corpus.
The problem of semantic parser induction and child language acquisition
are both similar to the problem of inducing a grammar and a
parsing model from a treebank such as the Penn treebank, except that
the trees are unordered logical forms, in which the preterminals
are not aligned with words in the target language, and there may be
noise and spurious distracting logical forms supported by the context
but irrelevant to the utterance.
The talk shows that this class of problem can be solved if the child
or machine initially parses with the entire space of possibilities
that universal grammar allows under the assumptions of the Combinatory
Categorial theory of grammar (CCG), and learns a statistical
parsing model for that space using EM-related methods such
as Variational Bayes learning.
This can be done without all-or-none "parameter-setting" or attendant
"triggers", and without invoking any "subset principle" of the kind
proposed in linguistic theory, provided the system is presented with a
representative sample of reasonably short string-meaning pairs from
the target language.
Bio: Mark Steedman is Professor of Cognitive Science in the School of
Informatics at the University of Edinburgh, to which he moved in 1998
from the University of Pennsylvania, where he taught as
Professor in the Department of Computer and Information Science. He
is a Fellow of the British Academy, the Royal Society of Edinburgh,
the American Association for Artificial Intelligence, and the European
Academy.
His research covers a range of problems in computational linguistics,
artificial intelligence, computer science, and cognitive science,
including syntax and semantics of natural language, and parsing and
comprehension of natural language discourse by humans and by machine
using Combinatory Categorial Grammar (CCG). Much of his current NLP
research concerns wide-coverage parsing for robust semantic
interpretation and natural language inference, and the problem of
inducing such grammars from data and grounded meaning representations,
including those arising in robotics domains. Some of his research
concerns the analysis of music using robust NLP methods.

Saturday, May 26, 2012
Lecture 18: the BabelNet APIs and other tools for working on the project
Lecture 17: seminars from the Sapienza NLP group (22/05/12)
Ph.D. students and postdocs in Prof. Navigli's group giving seminars on their research activity.


Lecture 16: knowledge-based WSD (18/05/12)
Knowledge-based Word Sense Disambiguation. The Lesk and Extended Lesk algorithm. Structural approaches: similarity measures and graph algorithms. Conceptual density. Structural Semantic Interconnections. Evaluation: precision, recall, F1, accuracy. Baselines. The Senseval and SemEval evaluation competitions. Applications of Word Sense Disambiguation. Issues: representation of word senses, domain WSD, the knowledge acquisition bottleneck.


Wednesday, May 16, 2012
Lecture 15: more on Word Sense Disambiguation (15/05/12)
Supervised Word Sense Disambiguation: pros and cons. Vector representation of context. Main supervised disambiguation paradigms: decision trees, neural networks, instance-based learning, Support Vector Machines. Unsupervised Word Sense Disambiguation: Word Sense Induction. Context-based clustering. Co-occurrence graphs: curvature clustering, HyperLex.


Friday, May 11, 2012
Lecture 14: project presentation and Word Sense Disambiguation (11/05/12)
The NLP projects are online (2012_project.pdf). Please start your discussion! Topics today: introduction to Word Sense Disambiguation (WSD). Motivation. The typical WSD framework. Lexical sample vs. all-words. WSD viewed as lexical substitution and cross-lingual lexical substitution. Knowledge resources. Representation of context: flat and structured representations. Main approaches to WSD: Supervised, unsupervised and knowledge-based WSD. Two important dimensions: supervision and knowledge.


Friday, May 4, 2012
Lecture 13: lexical semantics and lexical resources (04/05/12)
Lexemes, lexicon, lemmas and word forms. Word senses: monosemy vs. polysemy. Special kinds of polysemy. Computational sense representations: enumeration vs. generation. Graded word sense assignment. Encoding word senses: paper dictionaries, thesauri, machine-readable dictionary, computational lexicons. WordNet. Wordnets in other languages. BabelNet.

Monday, April 30, 2012
Seminar by Prof. Iryna Gurevych: How to UBY - a Large-Scale Unified Lexical-Semantic Resource (30/04/12)
Title: How to UBY - a Large-Scale Unified Lexical-Semantic Resource
Speaker: Iryna Gurevych
 Download the presentation
Download the presentation
Abstract: The talk will present UBY, a large-scale resource integration
project based on the Lexical Markup Framework (LMF, ISO 24613:2008).
Currently, nine lexicons in two languages (English and German) have been
integrated: WordNet, GermaNet, FrameNet, VerbNet, Wikipedia (DE/EN),
Wiktionary (DE/EN), and OmegaWiki. All resources have been mapped to the
LMF-based model and imported into an SQL-DB. The UBY-API, a common Java
software library, provides access to all data in the database. The nine
lexicons are densely interlinked using monolingual and cross-lingual sense
alignments. These sense alignments yield enriched sense representations
and increased coverage. A sense alignment framework has been developed for
automatically aligning any pair of resources mono- or cross-lingually. As
an example, the talk will report on the automatic alignment of WordNet and
Wiktionary. Further information on UBY and UBY-API is available at:
http://www.ukp.tu-darmstadt.

Bio: Iryna Gurevych leads the UKP Lab in the Department of Computer
Science of the Technische Universität Darmstadt (UKP-TUDA) and at the
Institute for Educational Research and Educational Information (UKP-DIPF)
in Frankfurt. She holds an endowed Lichtenberg-Chair "Ubiquitous Knowledge
Processing" of the Volkswagen Foundation. Her research in NLP primarily concerns applied lexical semantic algorithms, such as computing semantic relatedness of words or paraphrase recognition, and their use to enhance the performance of NLP tasks, such as information retrieval, question answering, or summarization
Speaker: Iryna Gurevych
Download the presentation Abstract: The talk will present UBY, a large-scale resource integration
project based on the Lexical Markup Framework (LMF, ISO 24613:2008).
Currently, nine lexicons in two languages (English and German) have been
integrated: WordNet, GermaNet, FrameNet, VerbNet, Wikipedia (DE/EN),
Wiktionary (DE/EN), and OmegaWiki. All resources have been mapped to the
LMF-based model and imported into an SQL-DB. The UBY-API, a common Java
software library, provides access to all data in the database. The nine
lexicons are densely interlinked using monolingual and cross-lingual sense
alignments. These sense alignments yield enriched sense representations
and increased coverage. A sense alignment framework has been developed for
automatically aligning any pair of resources mono- or cross-lingually. As
an example, the talk will report on the automatic alignment of WordNet and
Wiktionary. Further information on UBY and UBY-API is available at:
http://www.ukp.tu-darmstadt.

Bio: Iryna Gurevych leads the UKP Lab in the Department of Computer
Science of the Technische Universität Darmstadt (UKP-TUDA) and at the
Institute for Educational Research and Educational Information (UKP-DIPF)
in Frankfurt. She holds an endowed Lichtenberg-Chair "Ubiquitous Knowledge
Processing" of the Volkswagen Foundation. Her research in NLP primarily concerns applied lexical semantic algorithms, such as computing semantic relatedness of words or paraphrase recognition, and their use to enhance the performance of NLP tasks, such as information retrieval, question answering, or summarization
Sunday, April 29, 2012
Mid-term exam (27/04/2012)
Mid-term exam: morphology and regular expressions, language modeling, probabilistic part-of-speech tagging, probabilistic syntactic parsing.


Lecture 12: introduction to semantics (20/04/12)
More exercises in preparation for the mid-term exam. Introduction to computational semantics. Syntax-driven semantic analysis. Semantic attachments. First-Order Logic. Lambda notation and lambda calculus for semantic representation.
Wednesday, April 18, 2012
Lecture 11: exercises (17/04/12)
Exercises about regular expressions for morphological analysis, n-gram models and stochastic part-of-speech tagging.


Friday, April 13, 2012
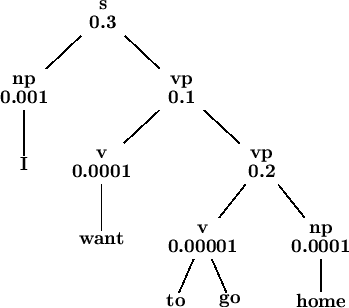
Lecture 10: syntax, part 2 (13/04/12)
Backtracking vs. dynamic programming for parsing. The CKY algorithm. The Earley algorithm. Probabilistic CFGs (PCFGs). PCFGs for disambiguation: the probabilistic CKY algorithm. PCFGs for language modeling.

Wednesday, April 4, 2012
Lecture 9: syntax, part 1 (03/04/12)
Introduction to syntax. Context-free grammars and languages. Treebanks. Normal forms. Dependency grammars. Syntactic parsing: top-down and bottom-up. Structural ambiguity.


Monday, April 2, 2012
Lecture 8: part-of-speech tagging, part 2 (30/03/12)
Stochastic part-of-speech tagging. Hidden markov models. Deleted interpolation. Transformation-based POS tagging. Handling out-of-vocabulary words.

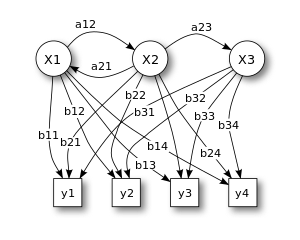
Lecture 7: part-of-speech tagging part 1 (27/03/12)
Introduction to part-of-speech (POS) tagging. POS tagsets: the Penn Treebank tagset and the Google Universal Tagset. Rule-based POS tagging. Introduction to stochastic POS tagging.


Tuesday, March 20, 2012
Lecture 6: perplexity, smoothing, interpolation (23/3/12)
After continuing with perplexity, we will introduce smoothing and interpolation techniques to deal with the issue of data sparsity.


Lecture 5: implementing a language model in Perl; perplexity (20/3/12)
We will see how to implement an n-gram language model in Perl in 20-30 lines of code (!). We will also discuss how to evaluate language models by means of perplexity.


Friday, March 16, 2012
Lecture 4: language models (16/3/12)
Today's lecture is about language models. You will discover how important language models are and how we can approximate real language with them. N-gram models (unigrams, bigrams, trigrams) will be discussed, together with their probability modeling and issues.


Thursday, March 15, 2012
Lecture 3: morphological analysis (13/3/12)
We continued our introduction to regular expressions in Perl. We also introduced finite state transducers for encoding the lexicon and orthographic rules.


Friday, March 9, 2012
Lecture 2: words, morphemes and regular expressions (9/3/12)
Today's lecture was focused on words and morphemes. Before delving into morphology and morphological analysis, we introduced regular expressions as a powerful tool to deal with different forms of a word.
Homework: watch 2001: a space odyssey!

Homework: watch 2001: a space odyssey!

Tuesday, March 6, 2012
Lecture 1: introduction (6/3/12)
We gave an introduction to the course and the field it is focused on, i.e., Natural Language Processing, with a focus on the Turing Test as a tool to understand whether "machines can think". We also discussed the pitfalls of the test, including Searle's Chinese Room argument.


Friday, February 10, 2012
Welcome!
Welcome to the blog of the Natural Language Processing course @ Sapienza University of Rome! The course is given by Prof. Roberto Navigli. It will be an exciting experience!
News

News
- The course syllabus is now available.
- All students are kindly requested to join the Google group for this course.
Subscribe to:
Comments (Atom)